Most teams building inbound email systems start with extraction. They focus on getting sender data, recipients, attachments, timestamps, and message fields into a useful event. That makes sense at first, because extraction is where the visible output appears. But reliability still has another step to survive. Even after parsing succeeds, two semantically identical emails can enter the pipeline and come out as slightly different payloads.
That is the quiet problem normalization solves. Before matching, routing, deduplication, or analytics can be trusted, the system needs one consistent internal representation of the same parsed event. Without that step, every downstream consumer inherits variation from upstream output: different sender object shapes, inconsistent timestamp formats, mixed empty-value policies, and unstable ordering in arrays that look harmless until retries or replays start producing different results.
In this post, I want to make the case that normalization is not cleanup work after parsing. It is the contract layer that makes parsed email output dependable for automation. For platform engineers and technical leaders, that means treating canonical field shape, participant ordering, attachment order, and timestamp precision as contract decisions early, not implementation details to patch later.
The hidden reliability layer starts with canonical field normalization
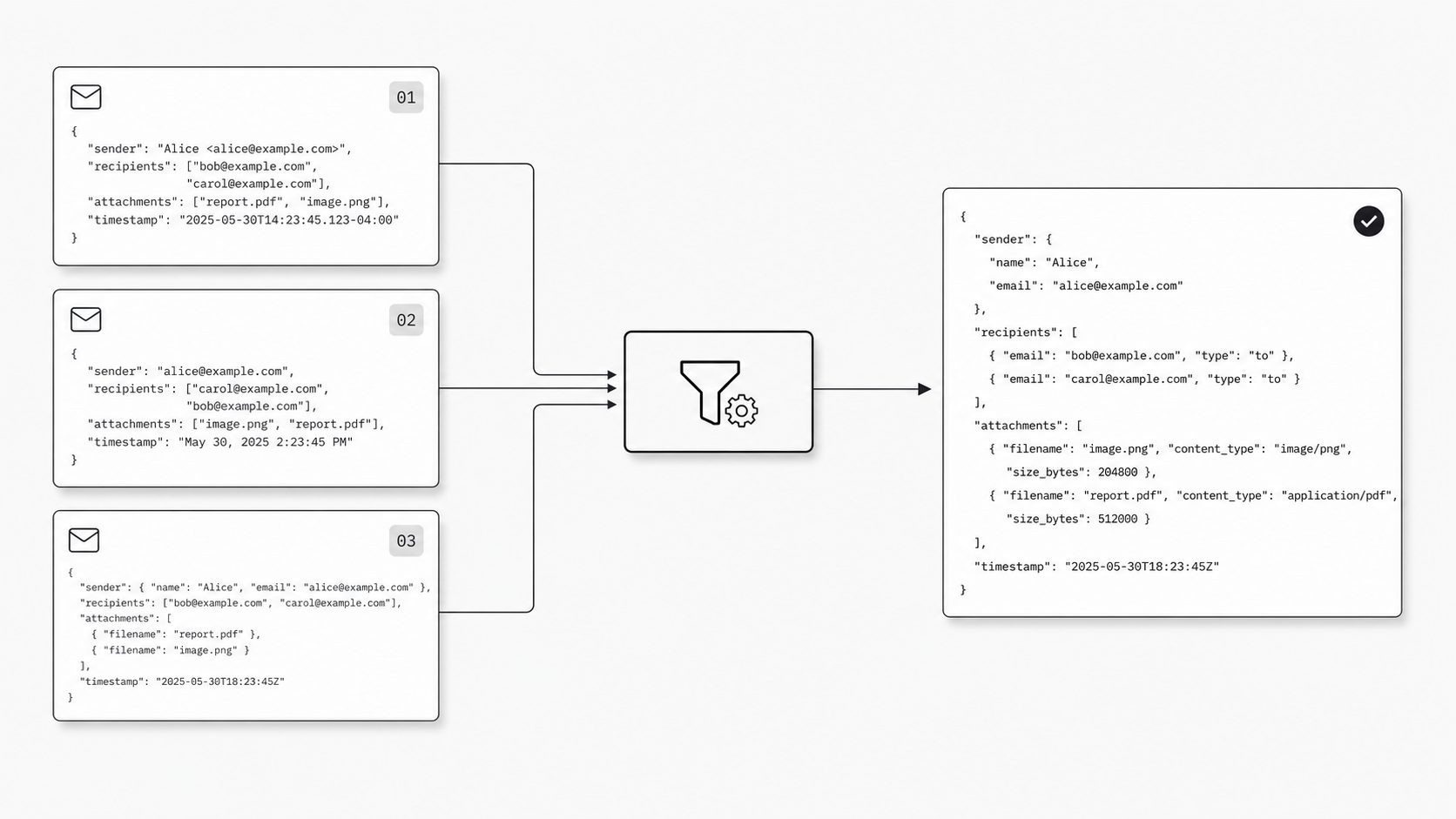
Teams can spend weeks refining extraction and routing, only to find that the same business event still arrives in slightly different structured shapes. One payload may include a display name in the sender object, another may split name and address, and another may format dates differently. Each payload can be technically usable, yet downstream automation now has to decide whether those shapes mean the same thing. That is why canonical field normalization acts as a hidden reliability layer before matching, routing, or mapping begins. (RFC 5322 - Internet Message Format)
This problem appears because parser output is still an interface, and interfaces need contracts. RFC 5322 is useful background for why email-derived data has many valid representations, but the normalization decision starts after parsing has produced fields your application can inspect. For platform engineers, the job at this layer is deciding what the system will treat as equivalent and storing that equivalence consistently.
In practice, a stable internal event should be boring: one sender object shape, one timestamp format, one policy for empty fields, and one naming pattern across the schema. That consistency reduces branch logic in downstream services and makes tests, reviews, and incident response easier because engineers are working from a stable contract rather than provider-specific variation.
Many teams lose reliability by normalizing only after matching starts. When one path emits one sender shape, another lowercases fields on the fly, and a third patches odd cases later, repeatability drops because transformation depends on message path. A dedicated normalization pass after extraction keeps the logic visible, testable, and reviewable.
Define a canonical form before tuning downstream rules. Choose the exact internal shape for names, addresses, selected headers, nulls, booleans, and timestamps, then require every parser, importer, and webhook path to emit that shape before matching begins. A quick test is simple: can two semantically identical parsed events produce the same structured JSON? Reliable systems answer that question early and in one place.
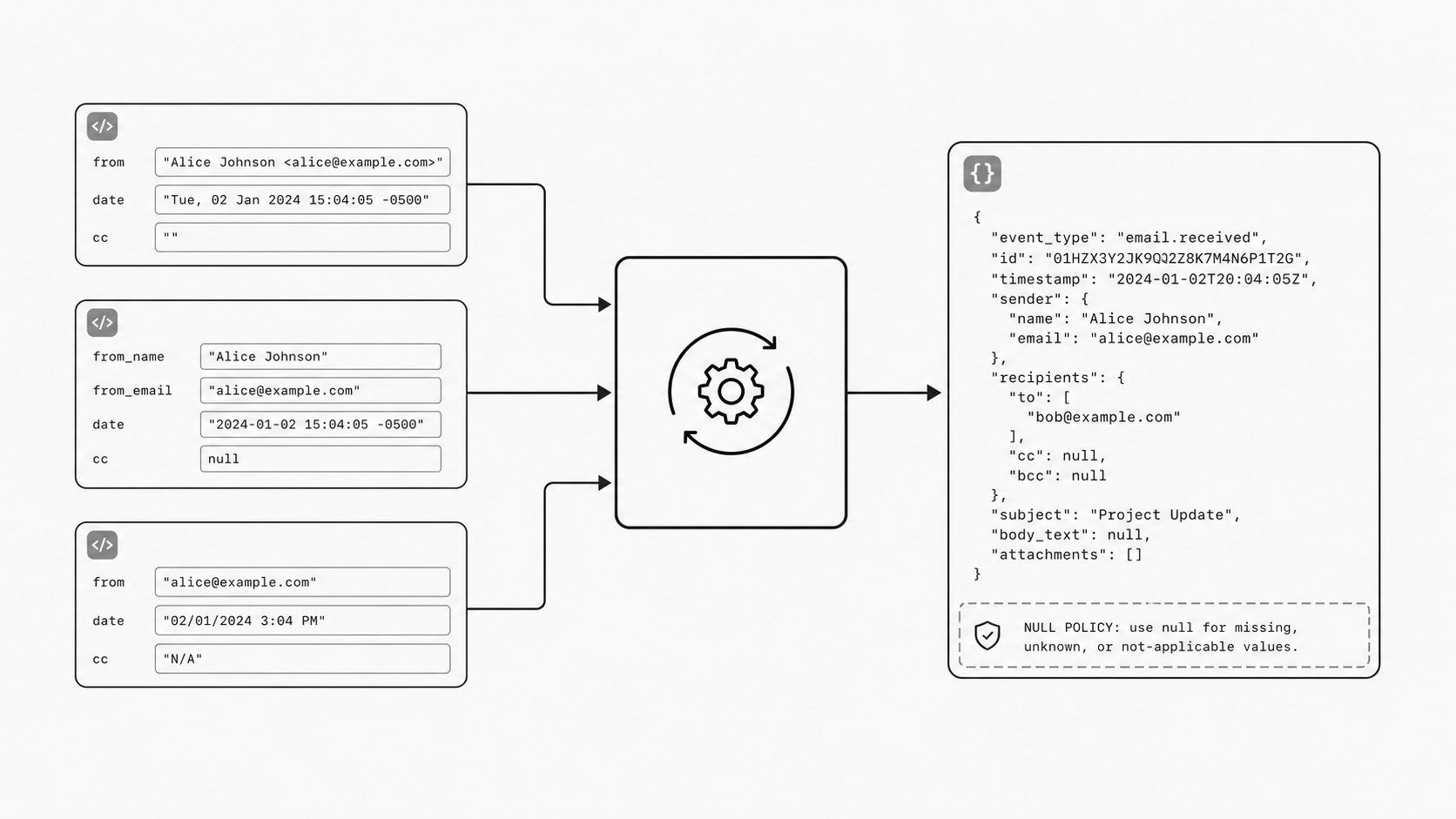
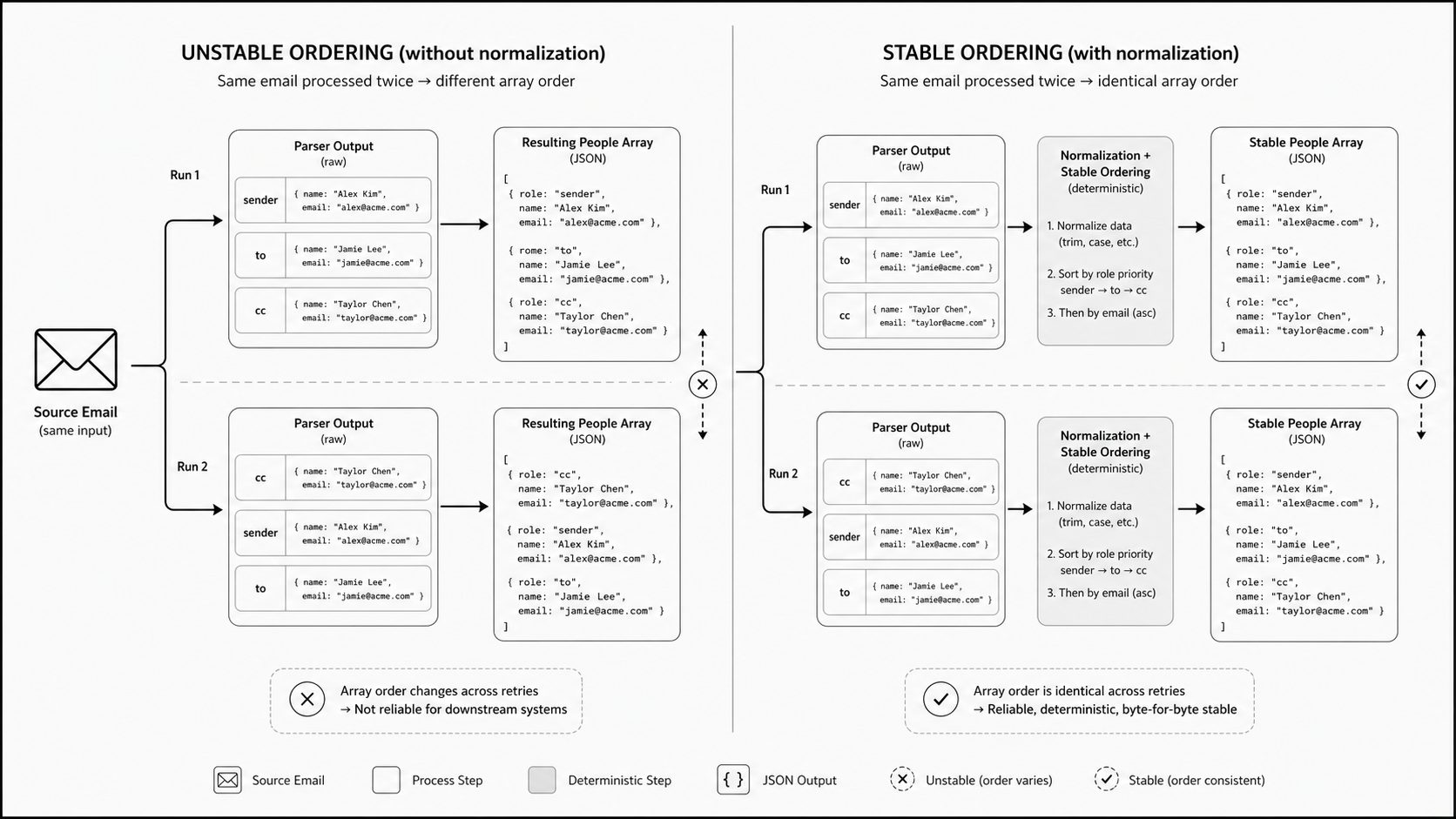
Here is where people-array ordering stability quietly protects trust
People-array ordering stability means sender and recipient collections are normalized and emitted in the same predictable order every time the same email is processed. In MailWebhook Generic JSON, people are grouped by role: from, to, optional reply_to, cc, and bcc. Each people array is sorted by email after addresses are lowercased and trimmed. I have seen teams build a clean email JSON schema, pass every parser test they wrote, and still lose trust in production because the people arrays kept moving around. The sender looked the same, the recipients were the same humans, and the message was the same event, yet one run produced a different array order than the next. That sounds small until a downstream service hashes the payload, compares snapshots, or decides whether an inbound email webhook is a duplicate based on structural sameness. (Stripe API Reference - Idempotent requests)
Order matters because systems consume structure, not intent. If repeated processing of the same message yields a different practical result, safe retries become harder to reason about. Stripe documents idempotent requests in that spirit: the same request key should return the same result on retry, and parameter mismatches are treated as misuse rather than harmless variation. That is a strong analogy for deterministic payload design in inbound email parsing. Raw email can expose participants through multiple headers and parser outputs, and those sources do not always arrive in a form that is ready for dependable downstream use. A parser may preserve encounter order from the source text, another may rebuild objects from a map, and a third may merge sender and recipient details after enrichment. If you do not choose one stable ordering rule, your structured email JSON output can drift even when the underlying message meaning has not changed.
Here is the kind of difference I mean. Both unnormalized outputs describe the same recipients, but a downstream hash or snapshot test sees two different payloads. The normalized shape keeps recipients in their role-specific arrays and sorts each array by email:
{
"run_a": {
"message": {
"to": [
{ "email": "ops@example.com" },
{ "email": "invoices@example.com" }
],
"cc": [
{ "email": "finance@example.com" }
]
}
},
"run_b": {
"message": {
"to": [
{ "email": "invoices@example.com" },
{ "email": "ops@example.com" }
],
"cc": [
{ "email": "finance@example.com" }
]
}
},
"normalized": {
"message": {
"to": [
{ "email": "invoices@example.com" },
{ "email": "ops@example.com" }
],
"cc": [
{ "email": "finance@example.com" }
]
}
}
}
Treat people-array ordering as part of the contract, not a formatting detail. For Generic JSON, that contract is role-specific people arrays sorted by email. Write the ordering rule down, test it with replays, and enforce it before matching, routing, or analytics begin. A simple check is whether the same raw message, when retried, replayed, or re-imported, produces sender and recipient arrays that are byte-for-byte stable after normalization. If not, trust is already leaking out of the system.
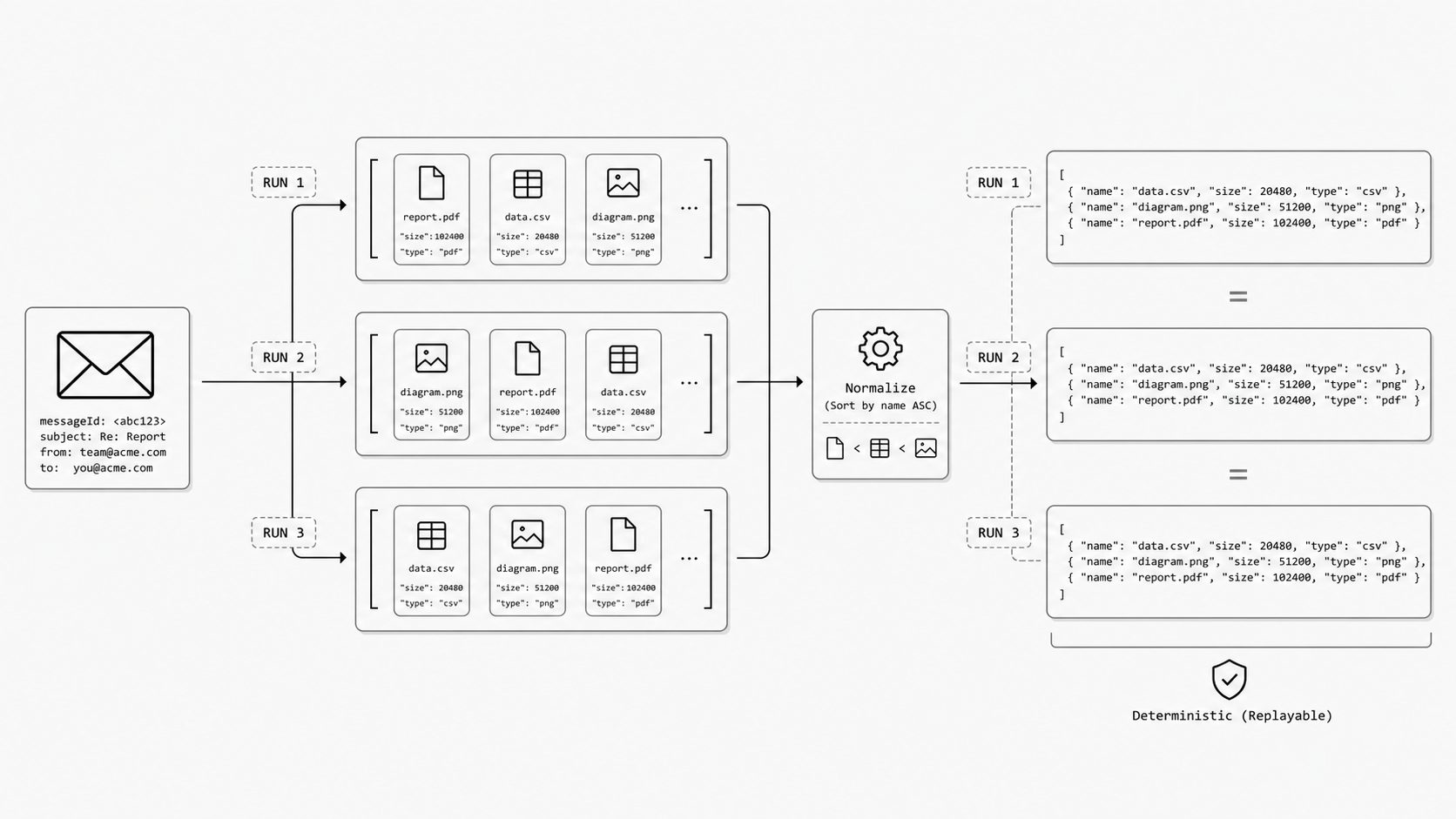
Attachments need deterministic order for replayable output
The same email can contain the same files and bytes yet still produce a different payload on replay if attachment order is left to chance. In an email JSON schema, that small shift can change diffs, break snapshot tests, and blur whether the system saw a new event or simply serialized the old one differently. (RFC 6376 - DomainKeys Identified Mail (DKIM) Signatures)
Attachment metadata is often assembled across multiple stages during inbound email parsing, so outputs can vary unless ordering is defined explicitly. One parser may preserve MIME encounter order, another may group inline files separately, and another may rebuild arrays from storage results. If no ordering rule exists, repeated processing can produce structurally different but equally valid outputs. That matters because replay safety, comparisons, and verification all work better with stable representation. DKIM is a useful precedent: it defines canonicalization algorithms to reduce variation in message representation before verification. In MailWebhook Generic JSON, attachments live under body.attachments, are sorted by (filename, size), and include id, filename, content_type, size, and is_inline, with optional content_id and sha256.
That gives the receiver stable metadata without embedding file bytes in the webhook body:
{
"body": {
"attachments": [
{
"id": "9f5a1ded-538d-4f5f-a7a9-d3eacf9e58a0",
"filename": "invoice-inv-1048.pdf",
"content_type": "application/pdf",
"size": 184233,
"is_inline": false,
"sha256": "059a0f5260487bbe663994de1fd641401fec76ac9f6bddfe5b53ae60d4bb2d86"
}
]
}
}
Use a simple replay test: run the same raw message through the pipeline multiple times and confirm the attachment array is identical each time. If it is, retries stay calmer, diffs stay meaningful, and production behavior is easier to trust. If it is not, make ordering an explicit contract instead of an accidental side effect.
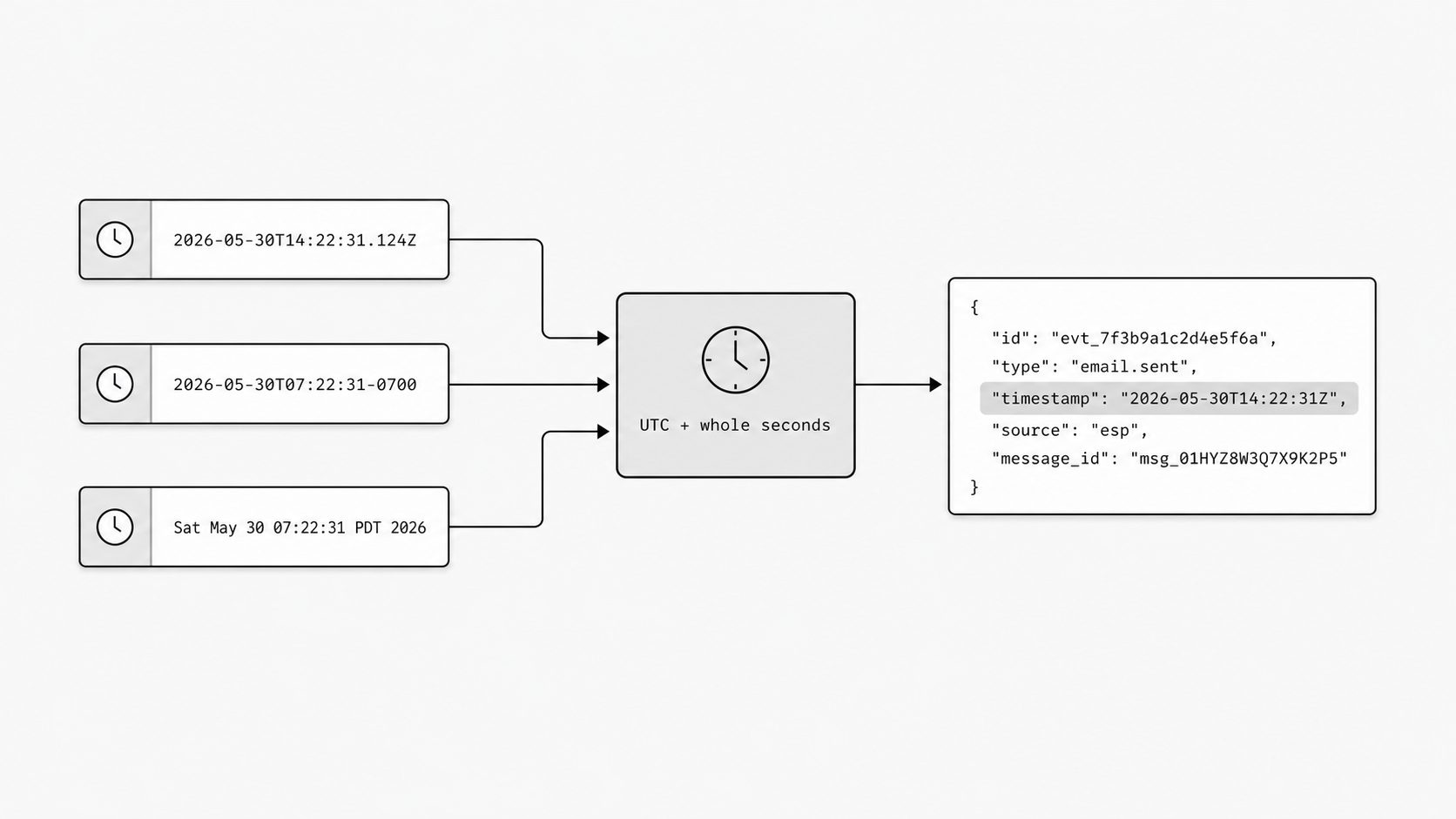
Time gets simpler when I choose whole-second UTC precision
Time is where a trustworthy pipeline can start to feel haunted. I replay the same message through an email parsing API, and the business meaning stays the same, yet one run says 2026-05-30T14:22:31.124Z, another keeps the original -0700 offset, and a third lands as a local server time string. That kind of drift makes a clean email JSON schema feel less stable than it looks, because engineers stop asking whether the event changed and start asking whether the clock changed shape.
You might be wondering: why do I care so much if the times all point to the same moment? I care because comparison, replay, and debugging all depend on one shared representation. RFC 5322 allows Internet message date-time fields to carry timezone offsets and flexible representational details, which means valid raw emails can describe time in more than one acceptable way before they ever reach my parser. If I pass that variation downstream, every consumer has to make its own judgment about equivalence.
That is where whole-second UTC precision earns its place. I choose one universal timezone, one precision, and one serialization rule before matching, routing, deduplication, or analytics begin. Now retries are easier to reason about because the same message produces the same timestamp shape on every pass. Incident review gets faster too. When logs, payloads, and internal events all speak the same time format, I can line up message receipt, parser execution, webhook delivery, and downstream writes without doing mental offset math.
The normalized field should collapse equivalent representations into one value:
{
"run_a": {
"meta": {
"received_at": "2026-05-30T14:22:31.124Z"
}
},
"run_b": {
"meta": {
"received_at": "2026-05-30T07:22:31-07:00"
}
},
"normalized": {
"meta": {
"received_at": "2026-05-30T14:22:31Z"
}
}
}
This also helps with boundary cases that quietly waste engineering time. A provider may preserve sub-second values from one ingestion path and drop them on another. A mailbox import may expose a numeric offset, while an inbound email parsing flow may already emit a UTC string. A replay job may use a different library default than the real-time path. Each of those choices can create structurally different output even when the underlying event is identical. When I normalize to whole-second UTC precision, I remove a class of accidental differences before they leak into tests, hashes, diffs, and audit trails.
I am careful here for one reason: time fields often become anchors in a deterministic JSON email payload. Teams sort by them, compare by them, and explain production behavior with them. If the timestamp contract is vague, every downstream rule inherits that vagueness.
My practical rule is simple: parse the raw message time, convert it to UTC, keep whole seconds, and emit one exact format everywhere. Then I test replay, reimport, and retry paths to confirm they produce the same timestamp value for the same message. Once that rule is in place, time becomes boring in the best way. Comparisons get cleaner, debugging gets shorter, and the stable JSON contract email systems need starts to hold under pressure.
Reliable inbound email processing is less about clever parsing than about disciplined sameness. If your system allows equivalent messages to turn into different structured outputs, every retry, replay, diff, and incident review becomes harder than it should be. The damage is subtle at first, then expensive.
That is why normalization deserves to sit near the start of the pipeline. A defined internal shape for fields, stable ordering for people and attachments, and one exact rule for timestamps give the rest of the stack something dependable to build on. Once those decisions are explicit and enforced everywhere, downstream logic gets simpler, test coverage gets stronger, and trust in the payload starts to compound.
For the product owner behind normalized output, see email to JSON.
The practical question is straightforward: when the same message is processed twice, do you get the same JSON back? If the answer is not an easy yes, normalization is where reliability work should begin.